


VLLM服务端启动ChineseErrorCorrector3-4B模型
先贴命令 vllm serve /www/models/Qwen/ChineseErrorCorrector3-4B \ --max-model-len 10240 \ &…
4天前24
windows右键管理
windows11设计之初是为了简化右键,但是很多功能都隐藏起来了,要不通过shift + 右键出来详细右键,要不就得点详情来看,通过以下方法可以直接换为旧版的右键菜单。开始菜单搜索cmd,以管理员身份打开运行以下命令reg.exe add "HKCU\Software…
2个月前 (05-27)136
从其他linux服务器拉取文件到当前服务器
项目需要,当前服务器通过堡垒机连接,不知道密码,但是其他服务器密码知道,也不能上传文件,所以,只能通过其他服务器将文件传输到当前服务器,其他服务器也没有安装nginx等网络服务,因此只能从过scp命令传输文件拉取单个文件scp root@192.168.1.100:/data/test.t…
2个月前 (05-18)184
从一台doris导入表结构和数据到另一台doris
Apache Doris 是一款开源、分布式、MPP 架构的 OLAP(在线分析型)数据库,主打海量数据实时多维分析、秒级 / 亚秒级查询、高并发报表与即席查询,非常适合构建实时数据仓库、BI 看板、用户行为分析、日志分析、湖仓融合等场景。 需要将数据从一台doris集群迁移到另一台doris服务器…
2个月前 (05-15)185
千万别用sql查询经纬度数据了,有更快的方式
最近需要查询学校周边的零售户有哪些,几千个学校,几十万零售户,用sql查询费了十几分钟才查询出来,后来问的AI,使用python代码,十几秒就能搞定。以下是完整的代码,可以作为参考。 def aaaaa(): import numpy as np import pandas…
2个月前 (05-09)154
Django + Doris CRC32 分表实战:问题汇总与解决方案
一次从零到一的 Django 分表实践,记录踩过的所有坑 前言最近在做一个零售户管理系统,需要处理十亿级的数据。考虑到 Doris 的强大分析能力,使用 Doris 作为数据库,并基于 CRC32 算法实现自动分表。过程并不顺利,遇到了各种各样的问题。记录这些问题及解决方案,希望能帮助到有类似…
2个月前 (05-06)125
一键删除**所有**Anaconda虚拟环境(安全、干净、彻底)
最安全、最简单、直接清空所有环境的方法,不用一个个删,也不会弄坏你的 base 环境。 核心命令(直接复制运行)先打开 Anaconda Prompt(Windows)或 终端(Mac/Linux),执行: 1. 查看所有环境(确认一下)conda env list 2. 批量删除所有自定义环…
3个月前 (04-27)133
Django 操作 Redis 完整教程
Redis 是一款高性能的内存数据库,Django 中常用来做缓存、会话存储、计数器、消息队列等。下面我带你从安装配置 → 基础使用 → 高级操作完整掌握 Django 操作 Redis 的方法。 一、环境准备1. 安装依赖包Django 操作 Redis 最常用的库是 django-redis(…
3个月前 (04-25)142
大数据处理技术方案拆分、异步、缓存、分批、冷热分离
一、拆分技术(分库分表):解决数据量膨胀瓶颈核心目标:通过数据的垂直/水平拆分,突破单库单表性能上限,实现业务隔离与高效查询。 按地市拆分(city_code) 逻辑:不同地市卷烟数据物理隔离,跨地市业务通过路由实现,查询天然不跨区。优势:贴合烟草行业地市化运营特性,避免跨库关联,大幅提升单…
3个月前 (04-24)135
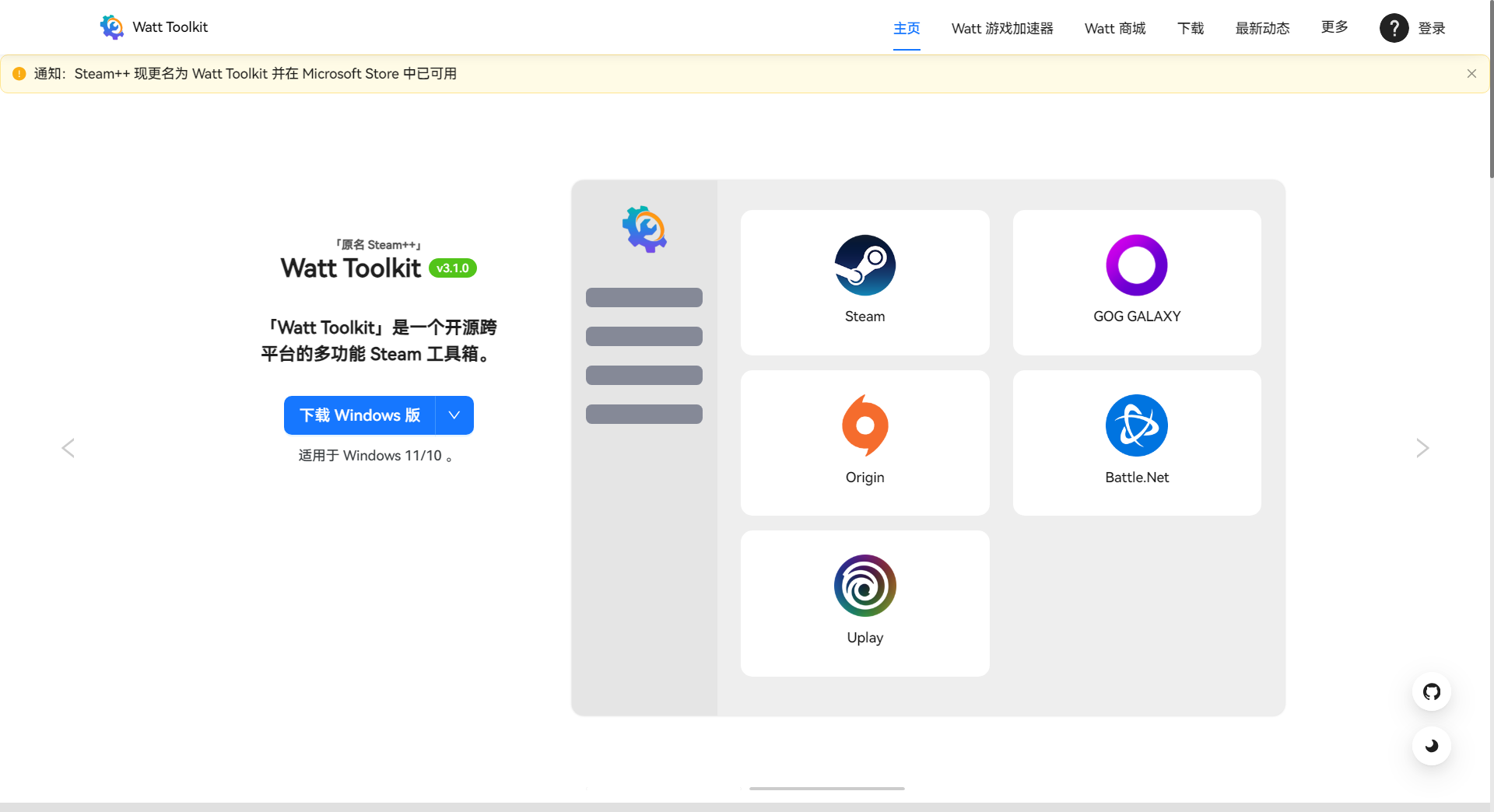
可用的github访问工具 Watt Toolkit
Watt Toolkit(原名 Steam++)是一款开源、跨平台的多功能游戏工具箱,主要面向使用 Steam、Epic、Uplay 等游戏平台 的玩家。它旨在优化游戏平台的使用体验,尤其针对国内用户常遇到的访问慢、加载卡顿、多账号切换繁琐等问题。 一、Watt Toolkit 是什么? 定…
3个月前 (04-22)2725


- 搜索
- 标签列表
- 热门阅读
-
2586 浏览学习
2088 浏览学习
988 浏览学习
882 浏览学习
749 浏览学习