FUNASR语音识别模型训练及使用
FunASR是一个基础语音识别工具包,提供多种功能,包括语音识别(ASR)、语音端点检测(VAD)、标点恢复、语言模型、说话人验证、说话人分离和多人对话语音识别等。FunASR提供了便捷的脚本和教程,支持预训练好的模型的推理与微调。
一、安装部署
新建python环境,python3.8以上、torch>=1.13
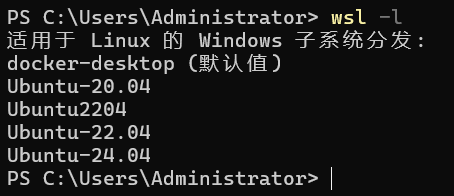
训练只支持在linux环境下,所以如果是windows电脑上的话最好使用wsl上创建个Ubuntu系统。
我使用的 Ubuntu-24.04。
好了,准备好以上环境就开始安装FunASR。
1、下载源码

解压目录下,经常用到的是我以下标柱的几个目录,后续我会讲具体怎么用。
2、安装库
进入到源码目录,运行以下命令,安装所需的库
<pre class="language-python">pip3 install -e ./
安装训练需要的库
<pre class="language-markup">pip3 install -U modelscope huggingface huggingface_hub
3、下载模型
运行以下代码,会自动下载模型到以下文件夹中。
<pre class="language-python">from funasr import AutoModel
model = AutoModel(model=”paraformer-zh”)
res = model.generate(input=”https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/vad_example.wav")
print(res)
可以直接将以上文件夹移动到项目目录中(最开始截图中models就是移动过来了的)
4、运行测试
以下是流式识别音频的测试代码,把音频文件改为你的音频,模型地址改为上一步存放的地址。我做了些音频处理,模型识别对音频有一定要求,必须是单声道、16k采样率的,因此做了判断处理。
<pre class="language-python">from funasr import AutoModel
chunk_size = [0, 10, 5] #[0, 10, 5] 600ms, [0, 8, 4] 480ms
encoder_chunk_look_back = 4 #number of chunks to lookback for encoder self-attention
decoder_chunk_look_back = 1 #number of encoder chunks to lookback for decoder cross-attention
model = AutoModel(model=”../models/iic/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-online_new”)
model.disable_update=True
import soundfile as sf
import librosa
import os
import numpy as np
wav_file = “wavfile/A0003_S005_0_G0001_female_16.wav”
wav_file = “wavfile/01.wav”
speech, sample_rate = sf.read(wav_file)
if speech.ndim == 1:
print(“单声道”)
elif speech.ndim == 2:
print(f”多声道,通道数:{speech.shape[1]}”)
print(‘采样率’,sample_rate)
if sample_rate != 16000:
speech = np.mean(speech, axis=1) # 各声道取平均
print(‘采样率不为16k,进行转换’)
speech = librosa.resample(speech, orig_sr=sample_rate, target_sr=16000)
print(speech)
if speech.ndim == 1:
print(“单声道”)
elif speech.ndim == 2:
print(f”多声道,通道数:{speech.shape[1]}”)
print(‘采样率’,sample_rate)
chunk_stride = chunk_size[1] * 960 # 600ms
cache = {}
total_chunk_num = int(len((speech)-1)/chunk_stride+1)
for i in range(total_chunk_num):
speech_chunk = speech[ichunk_stride:(i+1)chunk_stride]
is_final = i == total_chunk_num - 1
res = model.generate(input=speech_chunk, cache=cache, is_final=is_final, chunk_size=chunk_size, encoder_chunk_look_back=encoder_chunk_look_back, decoder_chunk_look_back=decoder_chunk_look_back)
print(res)
以下是识别效果
二、准备数据
训练模型最重要的就是准备训练所需的数据,标柱准确的文字。以下是具体操作步骤。
1、准备数据和标柱
这一步可以查看之前的文章
使用label-studio进行标柱,导出结果是一个json文件,效果如下,主要是视频每段的开始结束时间和对应识别的文字。
2、处理音频和数据
FunASR模型训练主要用到 jsonl 文件,它是从一个识别文本txt文件和识别音频目录地址scp文件通过 scp2jsonl 命令生成。
因此需要准备一个txt和scp文件。
将上一步准备的json文件和识别的yinpwav文件放到一个目录下,运行以下代码(记得修改文件名和地址),程序会自动生成以上两个文件。
<pre class="language-python">import json
import os
from pydub import AudioSegment
import soundfile as sf
def ensure_directory_exists(directory):
if not os.path.exists(directory):
os.makedirs(directory)
def parse_json(json_data):
annotations = json_data[0].get(‘annotations’, [])
data_list = []
for ann in annotations:
result = ann.get(‘result’, [])
for res in result:
if res.get(‘type’) == ‘textarea’ and res.get(‘origin’) == ‘manual’:
label_value = res.get(‘value’, {})
start = label_value.get(‘start’)
end = label_value.get(‘end’)
text = label_value.get(‘text’)[0]
id = res.get(‘id’)
data_list.append({
‘id’: id,
‘start’: start,
‘end’: end,
‘text’: text
})
return data_list
def split_audio_and_generate_files(json_file_path, original_audio_path, output_dir):
# 读取 JSON 文件
with open(json_file_path, 'r', encoding='utf-8') as f:
json_data = json.load(f)
# 解析数据
data_list = parse_json(json_data)
# 确保输出目录存在
ensure_directory_exists(output_dir)
txt_file_path = os.path.join(output_dir, 'train.txt')
scp_file_path = os.path.join(output_dir, 'train.scp')
# 加载原始音频文件
try:
audio = AudioSegment.from_wav(original_audio_path)
except Exception as e:
print(f"无法加载音频文件 {original_audio_path}: {e}")
return
txt_lines = []
scp_lines = []
for data in data_list:
id_ = data['id']
start_ms = data['start'] * 1000 # 转换为毫秒
end_ms = data['end'] * 1000 # 转换为毫秒
text = data['text']
# 分割音频
segment = audio[start_ms:end_ms]
# 定义输出音频文件路径
audio_filename = f"{id_}.wav"
wavfiles = os.path.join(output_dir, 'wavfiles')
ensure_directory_exists(wavfiles)
audio_filepath = os.path.join(wavfiles, audio_filename)
# 导出音频片段
try:
segment.export(audio_filepath, format="wav")
except Exception as e:
print(f"无法导出音频文件 {audio_filepath}: {e}")
continue
# 写入 TXT 文件
txt_line = f"{id_}\t{text}\n"
txt_lines.append(txt_line)
# 写入 SCP 文件
scp_line = f"{id_}\t{audio_filepath}\n"
scp_lines.append(scp_line)
# 保存 TXT 文件
with open(txt_file_path, 'w', encoding='utf-8') as txt_file:
txt_file.writelines(txt_lines)
# 保存 SCP 文件
with open(scp_file_path, 'w', encoding='utf-8') as scp_file:
scp_file.writelines(scp_lines)
print(f"处理完成。")
print(f"TXT 文件已保存至: {txt_file_path}")
print(f"SCP 文件已保存至: {scp_file_path}")from pydub import AudioSegment
import os
def convert_wav_to_mono_16k(input_wav_path, output_wav_path=None):
# 加载音频文件
audio = AudioSegment.from_wav(input_wav_path)
print(f"原始音频信息:")
print(f" 声道数: {audio.channels}")
print(f" 采样宽度: {audio.sample_width * 8} bit")
print(f" 帧率 (采样率): {audio.frame_rate} Hz")
# 转为单声道
if audio.channels > 1:
print("检测到多声道,正在转为单声道...")
audio = audio.set_channels(1)
else:
print("音频已经是单声道,无需转换。")
# 转为16kHz采样率
target_sample_rate = 16000
if audio.frame_rate != target_sample_rate:
print(f"当前采样率为 {audio.frame_rate} Hz,正在转为 {target_sample_rate} Hz...")
audio = audio.set_frame_rate(target_sample_rate)
else:
print(f"音频采样率已经是 {target_sample_rate} Hz,无需转换。")
# 设置输出路径
if output_wav_path is None:
base, ext = os.path.splitext(input_wav_path)
output_wav_path = f"{base}_converted{ext}"
# 导出为wav格式,确保是16bit PCM
audio.export(output_wav_path, format="wav", parameters=["-ac", "1", "-ar", "16000", "-sample_fmt", "s16"])
print(f"转换完成!文件已保存至: {output_wav_path}")
return output_wav_pathif name == “main“:
# JSON 文件路径(请根据实际情况修改)
json_file_path = 'data/data.json'
# 原始音频文件路径(请根据实际情况修改)
original_audio_path = 'data/01.wav'
original_audio_path = convert_wav_to_mono_16k(original_audio_path)
speech, sample_rate = sf.read(original_audio_path)
if speech.ndim == 1:
print("单声道")
elif speech.ndim == 2:
print(f"多声道,通道数:{speech.shape[1]}")
print('采样率',sample_rate)
# 输出目录(请根据实际情况修改)
output_dir = 'traindata' # 例如: 'split_audio_files'
split_audio_and_generate_files(json_file_path, original_audio_path, output_dir)运行结果
三、模型训练
进入到以下目录中,将准备好的数据放到训练数据目录中
修改训练脚本,修改训练模型的目录,修改使用的数据集目录。可以根据模型和数据量修改训练参数
<pre class="language-python">workspace=pwd
which gpu to train or finetune
export CUDA_VISIBLE_DEVICES=”0”
gpu_num=$(echo $CUDA_VISIBLE_DEVICES | awk -F “,” ‘{print NF}’)
model_name from model_hub, or model_dir in local path
option 1, download model automatically
model_name_or_model_dir=”../../../models/iic/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-online”
option 2, download model by git
#local_path_root=${workspace}/modelscope_models
#mkdir -p ${local_path_root}/${model_name_or_model_dir}
#git clone https://www.modelscope.cn/${model_name_or_model_dir}.git ${local_path_root}/${model_name_or_model_dir}
#model_name_or_model_dir=${local_path_root}/${model_name_or_model_dir}
data dir, which contains: train.json, val.json
data_dir=”../../../data/list”
data_dir=”./traindata”
train_data=”${data_dir}/train.jsonl”
val_data=”${data_dir}/val.jsonl”
generate train.jsonl and val.jsonl from wav.scp and text.txt
scp2jsonl
++scp_file_list=’[“./traindata/train.scp”, “./traindata/train.txt”]’
++data_type_list=’[“source”, “target”]’
++jsonl_file_out=”${train_data}”
scp2jsonl
++scp_file_list=’[“./traindata/val.scp”, “./traindata/val.txt”]’
++data_type_list=’[“source”, “target”]’
++jsonl_file_out=”${val_data}”
exp output dir
output_dir=”./outputs”
log_file=”${output_dir}/log.txt”
deepspeed_config=${workspace}/../../ds_stage1.json
mkdir -p ${output_dir}
echo “log_file: ${log_file}”
DISTRIBUTED_ARGS=”
–nnodes ${WORLD_SIZE:-1}
–nproc_per_node $gpu_num
–node_rank ${RANK:-0}
–master_addr ${MASTER_ADDR:-127.0.0.1}
–master_port ${MASTER_PORT:-26669}
“
echo $DISTRIBUTED_ARGS
torchrun $DISTRIBUTED_ARGS
../../../funasr/bin/train_ds.py
++model=”${model_name_or_model_dir}”
++train_data_set_list=”${train_data}”
++valid_data_set_list=”${val_data}”
++dataset=”AudioDataset”
++dataset_conf.index_ds=”IndexDSJsonl”
++dataset_conf.data_split_num=1
++dataset_conf.batch_sampler=”BatchSampler”
++dataset_conf.batch_size=12000
++dataset_conf.sort_size=1024
++dataset_conf.batch_type=”token”
++dataset_conf.num_workers=4
++train_conf.max_epoch=100
++train_conf.log_interval=1
++train_conf.resume=true
++train_conf.validate_interval=2000
++train_conf.save_checkpoint_interval=2000
++train_conf.keep_nbest_models=20
++train_conf.avg_nbest_model=10
++train_conf.use_deepspeed=false
++train_conf.deepspeed_config=${deepspeed_config}
++optim_conf.lr=0.0002
++output_dir=”${output_dir}” &> ${log_file}
运行以下命令开始训练
<pre class="language-c">bash finetune.sh
训练完后在输出目录下会生成以下文件
在源码根目录下运行以下代码
<pre class="language-markup">tensorboard –logdir examples/industrial_data_pretraining/paraformer_streaming/outputs
在浏览器上打开 可视化地址
可以可视化查看模型训练情况。
四、测试结果
1、复制一份模型目录
将训练完的模型文件复制覆盖新目录下的模型文件。
运行第一步的测试代码测试效果。
备注:目录文件说明