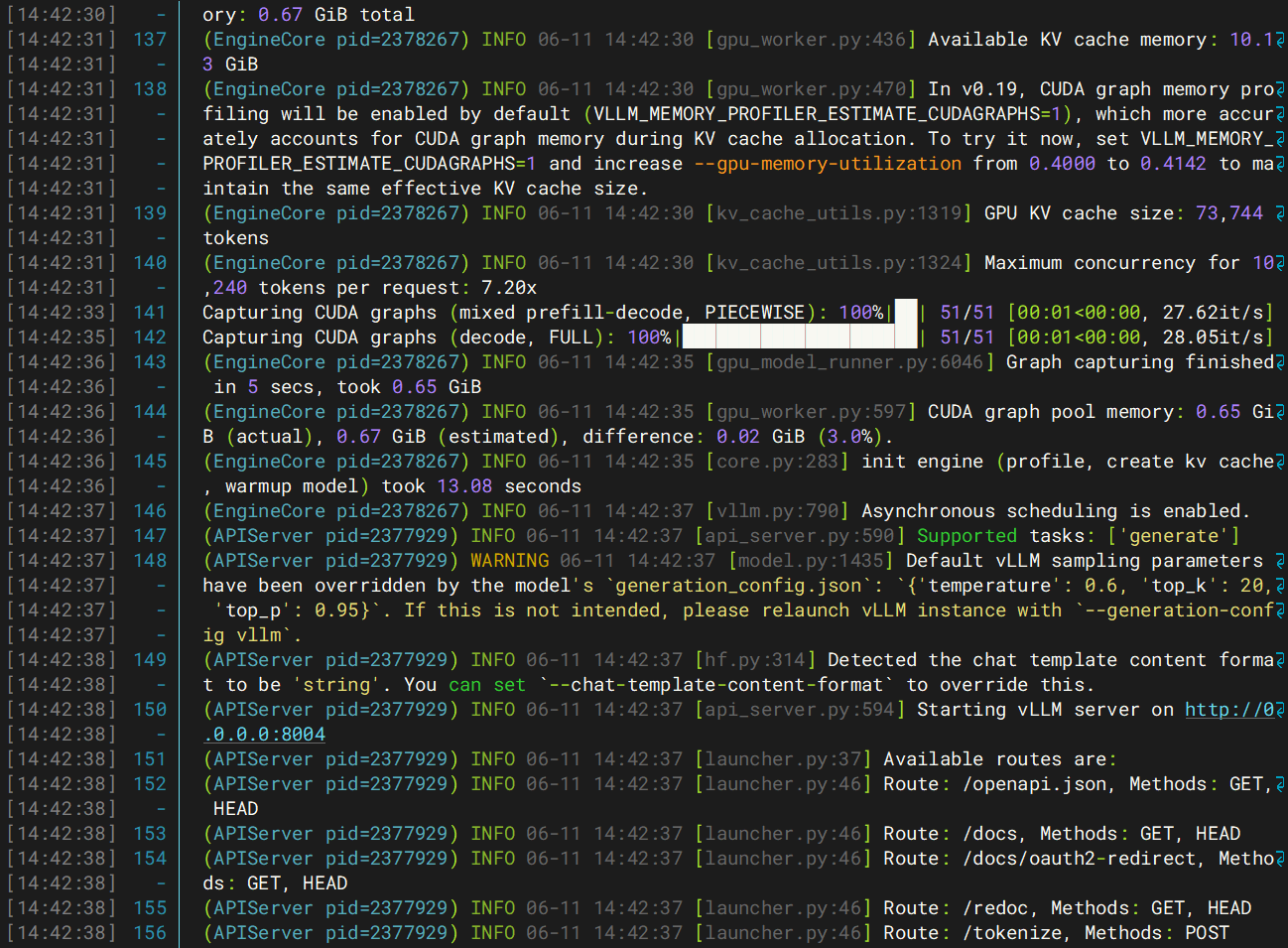
大数据处理技术方案拆分、异步、缓存、分批、冷热分离

一、拆分技术(分库分表):解决数据量膨胀瓶颈
核心目标:通过数据的垂直/水平拆分,突破单库单表性能上限,实现业务隔离与高效查询。
- 按地市拆分(city_code)
- 逻辑:不同地市卷烟数据物理隔离,跨地市业务通过路由实现,查询天然不跨区。
- 优势:贴合烟草行业地市化运营特性,避免跨库关联,大幅提升单业务查询性能。
- 按时间拆分(周/日)
- 逻辑:订单数据按周/日粒度分表,环比同比类统计仅需查询对应周期数据。
- 优势:时间范围查询性能提升数倍,避免扫描全表数据。
- 哈希拆分(retailer_id)
- 逻辑:采用
CRC32(retailer_id) % 64哈希算法,实现零售户数据均匀分布到64个分表,全平台路由规则统一。 - 优势:避免数据倾斜,保障单零售户数据查询的高效性。
- 逻辑:采用
- 三层分表规则(地市 + 周 + 零售户哈希)
- 适用场景:订单表等高频写入、高频查询的核心业务表。
- 优势:兼顾业务隔离、时间查询与单主体数据查询的性能,是烟草订单场景的最佳实践。
- 多数据库兼容
- 支持MySQL、PostgreSQL、Doris、ADB等主流数据库,适配在线事务、离线分析等不同业务场景。
二、异步处理:削峰填谷,提升系统吞吐量
核心目标:将同步耗时操作转为异步处理,降低主链路响应时间,提升系统并发承载能力。
- 消息队列MQ(Kafka/RocketMQ)
- 场景:订单削峰、业务解耦、订单入库异步化。
- 优势:抗住流量峰值,避免突发流量压垮数据库,同时实现业务模块解耦。
- 异步线程池(Java @Async / Python ThreadPool)
- 场景:非核心业务逻辑异步执行,如日志记录、通知推送、非实时统计计算。
- 优势:主流程快速响应,后台线程池处理耗时任务,提升用户体验。
- 定时调度异步(DataWorks/XXL-Job)
- 场景:凌晨离线跑批,计算环比同比、日/周/月统计报表。
- 优势:避开业务高峰期,不影响日间业务性能,同时利用闲时资源完成大数据量计算。
- CDC异步同步(Canal/Flink CDC)
- 场景:MySQL业务数据实时同步至Doris数仓,实现业务库与分析库的解耦。
- 优势:低延迟同步数据,业务库无额外压力,数仓可支撑复杂分析查询。
- HTTP异步接口(DataWorks回调)
- 场景:DataWorks跑批完成后,异步调用业务系统接口推送计算结果。
- 优势:避免跑批任务阻塞,实现业务系统与调度平台的解耦。
三、缓存技术:减少数据库访问,提升热点数据查询性能
核心目标:构建多级缓存体系,实现99%以上请求不直接访问数据库,降低数据库压力。
- 本地缓存(Caffeine)
- 场景:存储字典数据、地市/卷烟白名单、配置信息等低频变更数据。
- 优势:读取速度极快,无网络开销,适合静态/半静态数据缓存。
- 分布式缓存(Redis)
- 场景:缓存零售户信息、订单详情、统计指标、热门商品数据。
- 优势:支持高并发读写,可设置过期时间,实现数据共享与一致性控制。
- 多级缓存架构(本地 → Redis → DB)
- 逻辑:优先读取本地缓存,未命中则读取Redis,仍未命中再查询数据库,同时回写缓存。
- 优势:多层级防护,大幅降低数据库访问压力,提升整体查询性能。
- 预计算缓存
- 场景:环比同比、同档位对标等复杂统计指标,提前计算并写入Redis。
- 优势:用户查询时直接读取缓存,响应时间从秒级降至毫秒级。
- 缓存安全策略
- 防穿透/击穿/雪崩:通过布隆过滤器、互斥锁、过期时间打散等机制保障缓存稳定性。
- 主动更新:定时刷新热点数据缓存,避免缓存与数据库数据不一致。
四、分批处理:避免全表操作,降低单次任务资源消耗
核心目标:将大数据量操作拆分为多批次执行,避免锁表、超时,保障业务稳定性。
- 主键分批
- 实现:通过
WHERE id BETWEEN 1 AND 1000按主键范围拆分数据,逐批处理。 - 优势:避免全表扫描,降低单次查询的IO与内存消耗。
- 实现:通过
- 游标分批
- 实现:通过
WHERE id > ? LIMIT 1000实现深度分页,避免OFFSET偏移量导致的性能问题。 - 优势:解决大数据量分页查询卡顿问题,实现高效分页。
- 实现:通过
- 分区分批
- 实现:按地市/分区维度拆分数据,仅扫描目标分区数据。
- 优势:结合数据库分区特性,大幅减少扫描数据量,提升处理效率。
- 调度分片
- 实现:DataWorks任务分片并行执行,例如40万零售户数据多实例并行处理。
- 优势:利用分布式调度能力,将小时级任务压缩至分钟级完成。
- 批量SQL操作
- 实现:批量INSERT/UPDATE操作,采用小事务提交,避免大事务锁表。
- 优势:减少数据库连接次数,同时避免大事务导致的锁等待与回滚风险。
五、冷热分离:优化存储成本,提升热数据性能
核心目标:将高频访问的热数据与低频访问的冷数据分离,实现性能与成本的平衡。
- 热数据(SSD存储)
- 范围:近30天订单数据、高频读写业务数据。
- 优势:SSD高IO性能保障高频查询与写入的低延迟。
- 冷数据(OSS/归档存储)
- 范围:30天以上历史订单数据、归档业务数据。
- 优势:低成本存储,大幅降低整体存储成本。
- 自动TTL策略
- 实现:Doris/ADB按时间自动将热数据转为冷数据,业务无感知。
- 优势:无需人工干预,自动完成数据冷热流转,保障业务连续性。
- 分区迁移
- 实现:按周/月分区,将过期分区自动迁移至OSS归档存储。
- 优势:结合分区特性,实现批量数据迁移,降低运维成本。
- 统一查询入口
- 实现:业务SQL无需修改,引擎自动路由冷热数据。
- 优势:对业务透明,无需改造代码即可实现冷热数据统一查询。
方案总结与落地建议
| 技术方向 | 核心解决问题 | 落地优先级 |
|---|---|---|
| 分库分表 | 数据量膨胀导致的性能瓶颈 | 高(订单等核心业务表优先) |
| 异步处理 | 高并发流量冲击、主链路响应慢 | 高(订单入库、统计计算优先) |
| 多级缓存 | 数据库访问压力大、热点数据查询慢 | 高(统计指标、基础数据优先) |
| 分批处理 | 大数据量操作超时、锁表 | 中(跑批任务、批量更新优先) |
| 冷热分离 | 存储成本高、热数据性能下降 | 中(历史订单、归档数据优先) |
落地时建议以核心业务场景(如订单处理、统计报表)为切入点,先搭建缓存与异步处理体系,再逐步推进分库分表与冷热分离改造,同时配套监控与压测,保障每一步改造的稳定性。